领域驱动设计DDD入门5:聚合
第五节课我们讲一个战术工具:聚合。聚合可以用于设计小型高效的对象集群,这些集群使用事务管理一致性约束。这节课先解释为什么要使用聚合,接下来介绍四个总体设计经验法则,然后是用于建模聚合的技术,随后考虑为什么在对聚合进行建模时应谨慎选择抽象级别。最后,我们考虑如何确保将聚合设计为可测试的单元。
每个有界上下文中都有几个概念。以敏捷项目管理产品为例,BacklogItem,Release,Sprint,以及Forum,Discussion,Post,Calendar和CalendarEntry。这些就是聚合。注意,这里还有一个概念,“Dicussion”,不是聚合是一个单独的值对象。我们不会关注值对象,我们将深入探讨聚合及其使用的原因。聚合具有几个不同的部分:聚合具有一个称为聚合根的根实体。聚合根实体还可以包含其他实体和值对象。在整个内部是事务边界。 这里有两个单独的聚合,其中聚合根实体将整个聚合代言。因此我们关注聚合根。它这是一个实体,它命名了整个聚合,并且具有全局唯一标识,因此该聚合对于所有其他实体或相同类型或不同类型的聚合而言是全局唯一的。 聚合就是事务一致性的边界。在聚合内,事务结束时所有内容必须保持一致。在操作的开始启动一个事务,然后传播到聚合整体。事务正在进行,聚合根据对其执行的操作进行更改,然后完成。之后,事务将提交。该事务没在聚合2的作用域。在另一个单独的事务中,聚合2将被更新。因此,聚合就是事务边界。
聚合设计四法则
我们称这些法则为“聚合设计经验法则”
第一是保护聚合边界内的业务不变量,第二是设计小的聚合,第三是只通过标识访问其他聚合,第四是通过最终一致性更新其他聚合。
保护业务不变量
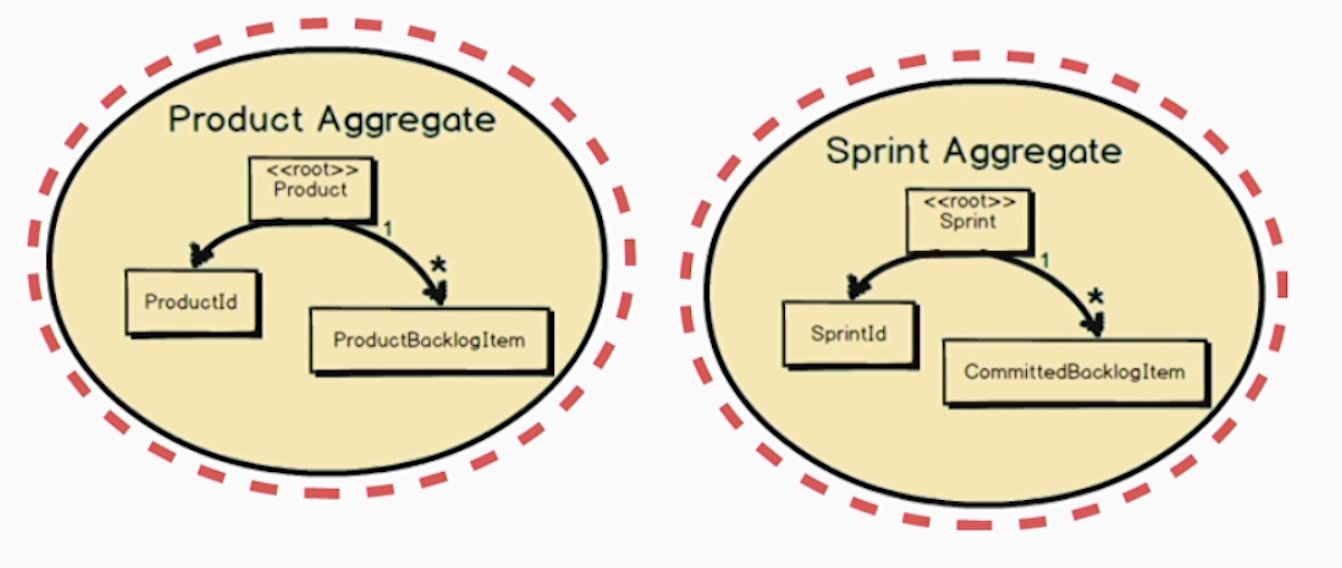
先看一个例子:产品聚合和冲刺聚合,每个聚合都被自身的事务控制。产品聚合的聚合根是product,它有引用指向ID及其产品待办项,注意和待办之间是一对多,那里是星号。冲刺聚合的聚合根是sprint实体,也有一个冲刺ID和一组已提交待办项,也是一对多关系。因为各自是独立的事务,所以它们的业务部变量就被保护起来了。
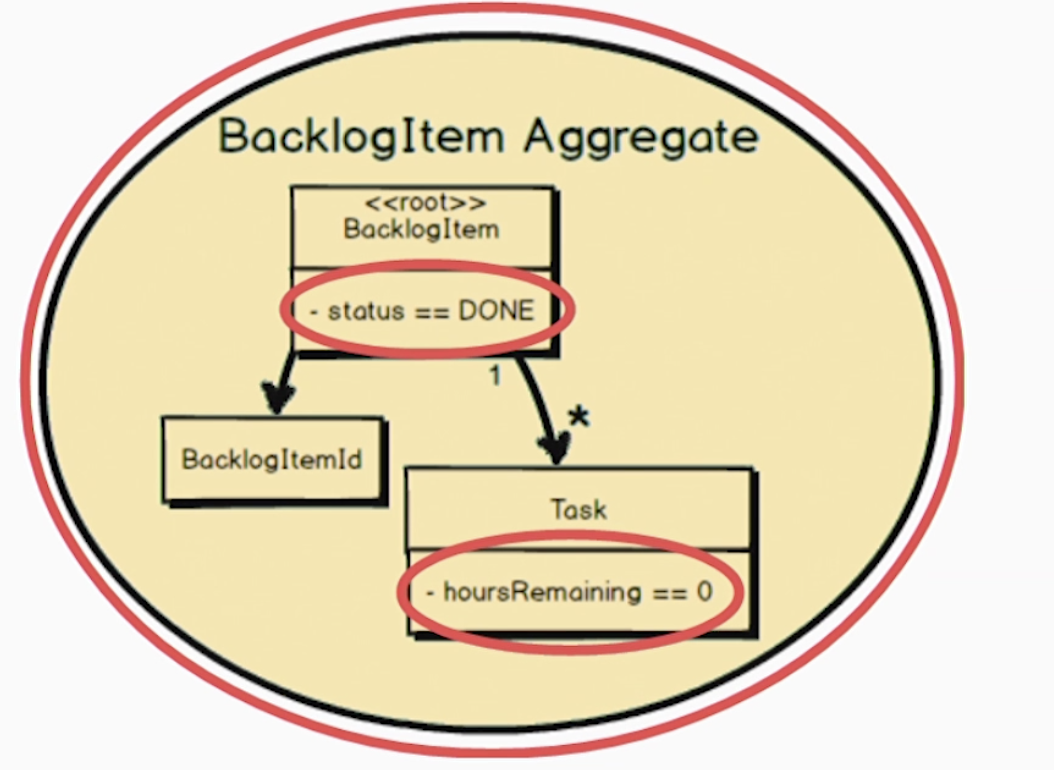
待办项也是聚合,聚合根是backlog item,也有ID和多个任务。注意待办有状态值,值可能取planned/committed/done。任务呢有剩余时间,是代表小时的整数。当待办项里的所有任务剩余时间都是0小时时,待办项的状态就是done。所以即使其他所有任务都是0了只要还有一个任务的小时数不为0,待办也是committed。只要最后一个任务的小时数设成0了,在同一个事务中就要把待置为done。这是业务上的一致性约束,必须遵守,只能在同一个事务完成。
聚合尽量小
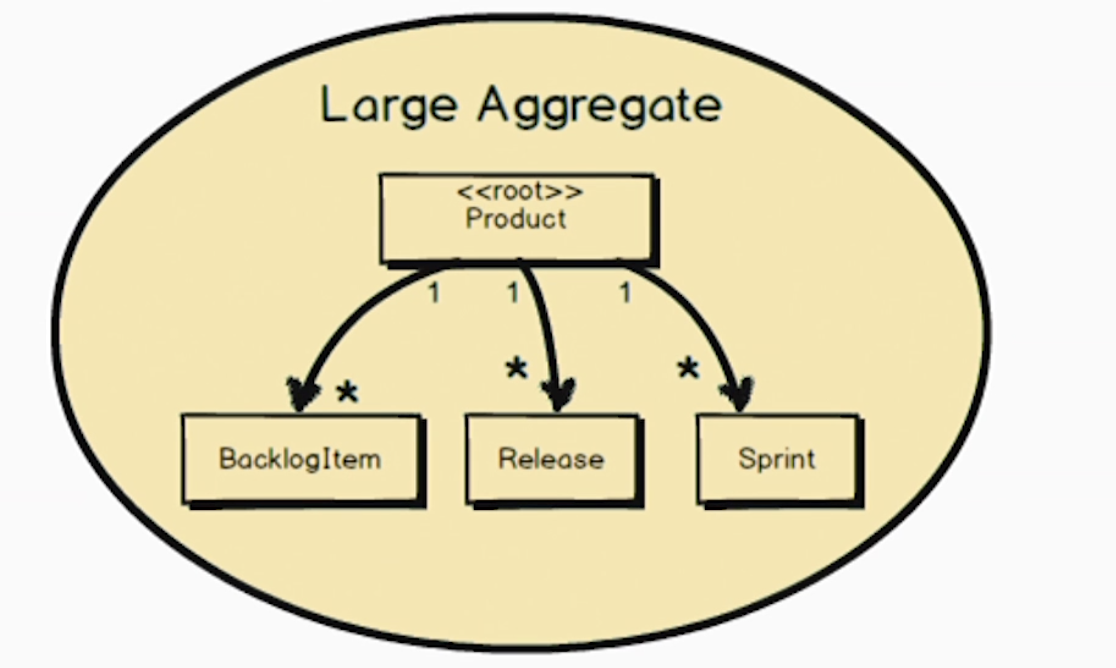
如图所示,可能会把产品所有的待办、发布、冲刺都放进产品聚合里。这样就太大了,需要拆分。因为有可能不同用户在不同事务会对同一个产品进行操作,这么大的聚合可能就会失败。比如有人修改发布有人修改待办,因为竞争的存在,同一时刻只会有一个事务成功,其他都会因为数据不一致而失败。另外太大的聚合占用内存也很大,没有必要啊,加载慢,GC也频繁了。
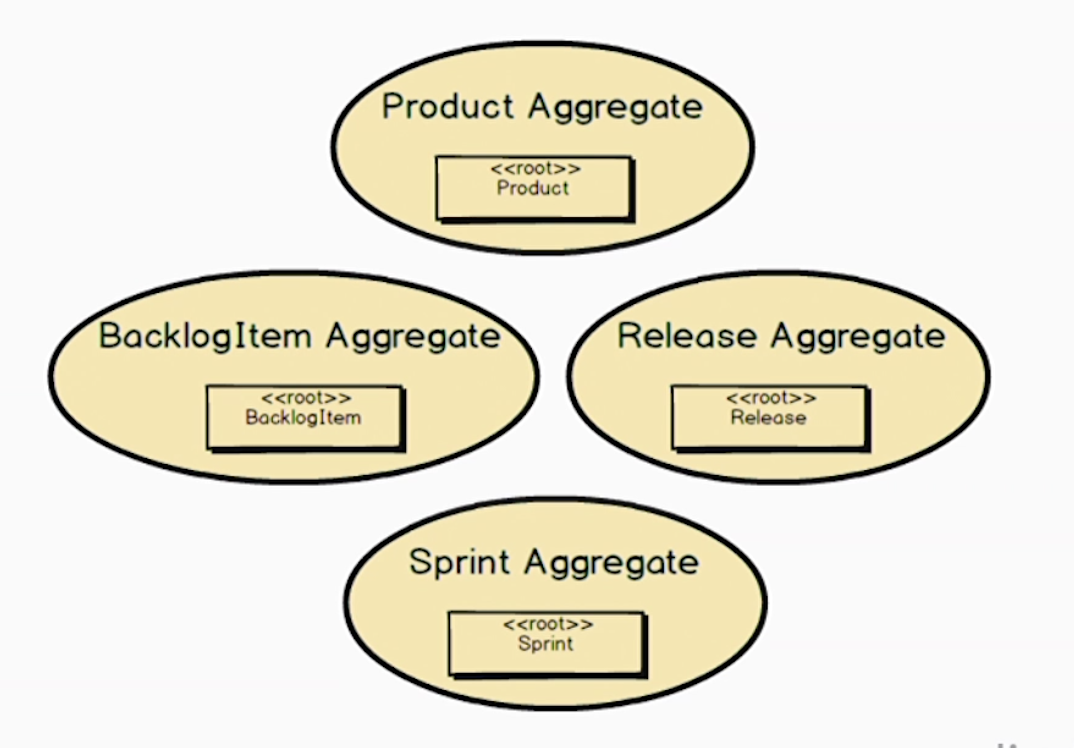
所以我们把它拆成4个聚合。产品聚合不再包含待办、发布和冲刺了。这样可以防止事务竞争,也降低了内存占用。反正是很大程度的改善。
通过标识引用
标识就是实体的ID。在上面我们的四个聚合中,新拆分的三个聚合都需要知道他们属于哪个产品,产品聚合是它们的父聚合。怎么知道呢?他们不需要有引用指向产品实体,而只要有实体ID的引用即可。
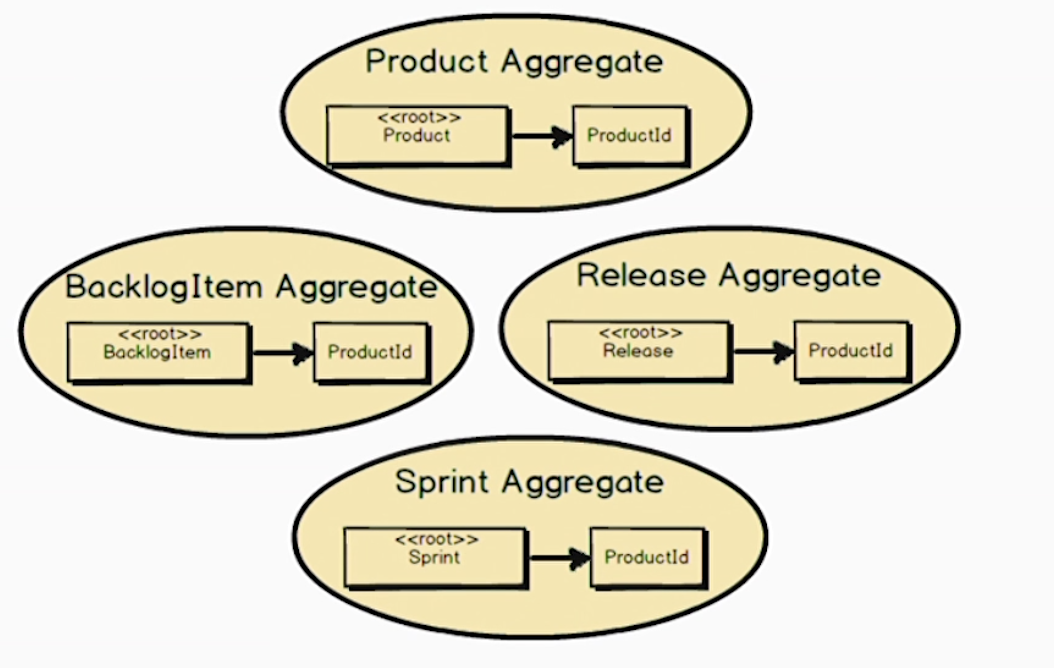
这么做的一个好处依然是占用内存小,另一个好处是当你修改子聚合的时候不会修改父聚合,不然也就破坏了第一个经验法则。
最终一致性
比如当待办被提交到冲刺时,待办是知道被提交到哪个冲刺的,它有冲刺的标识。事务完成时,这个待办关联的冲刺ID就被持久化了。但这时候冲刺还不知道有新的待办提交过来,但最终冲刺聚合会在一个新事务中记录有待办加入了。为什么?因为待办提交的时候会发布提交事件,敏捷项目管理软件会对这个事件做出响应,发现对冲刺有影响,于是冲刺更新自己的信息。原理是什么?就是“发布有界上下文”,三个小聚合都在这个上下文中,通过消息机制完成同步。订阅有界上下文会接收到事件消息,冲刺就是提交事件的相关方(第二堂课中说过)。
聚合模型
首先要警惕“贫血模型”。贫血模型容易上手,很多人陷入其中不能自拔。贫血模型就是模型里面没有任何行为,只有一大堆的getter/setter。
那怎么办呢?首先要记住聚合是事务一致性边界。你肯定会为聚合建模聚合根实体的,根还可能引用其他实体,也可能引用其他值对象。你肯定也会为聚合根起一个和聚合一样的名字。
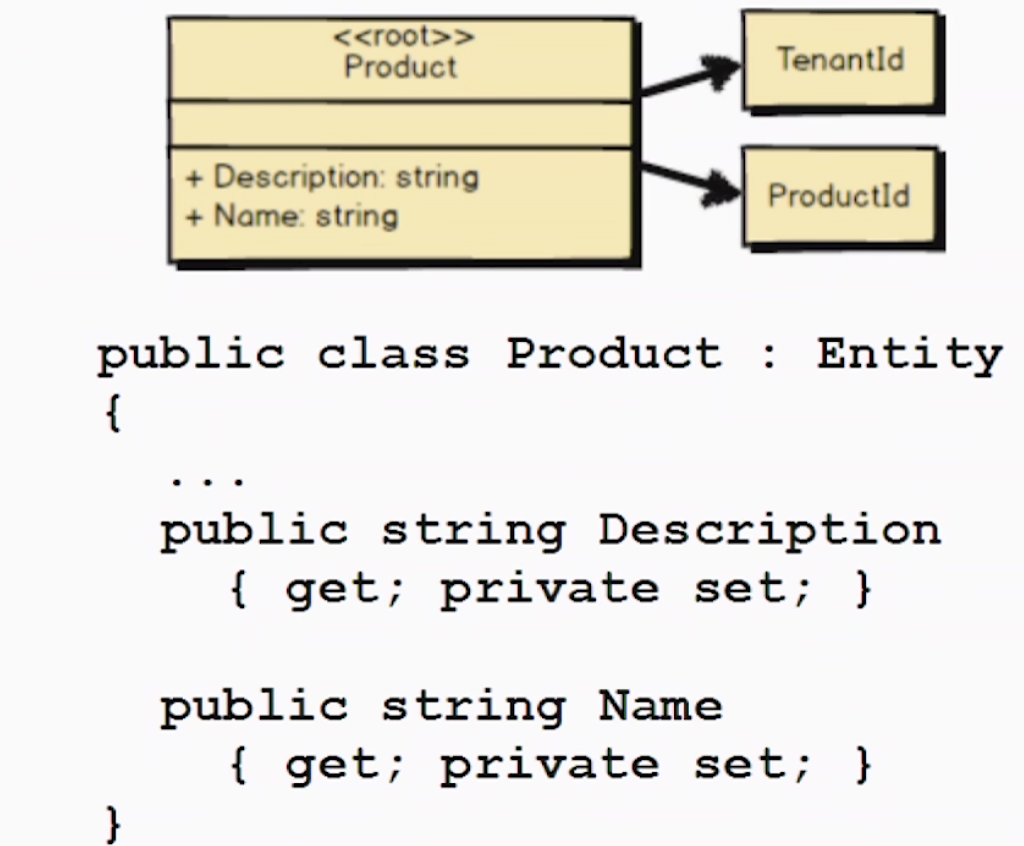
比如这个产品聚合的聚合根就叫产品product。从代码中可以看到这个根实体继承了Entity类,当然这里看不出它的必要性。根内部呢,引用了租户ID和产品ID。产品还有两个属性,名字和描述,都是字符串。访问控制呢?get是公开的,set是私有的。为啥会有私有的?这很重要,你注意不到就可能变成贫血模型。贫血模型中,不经过任何行为就能修改属性,而这里你不能访问setter了,只能通过行为来控制。行为才是公开的,用户必须使用行为。
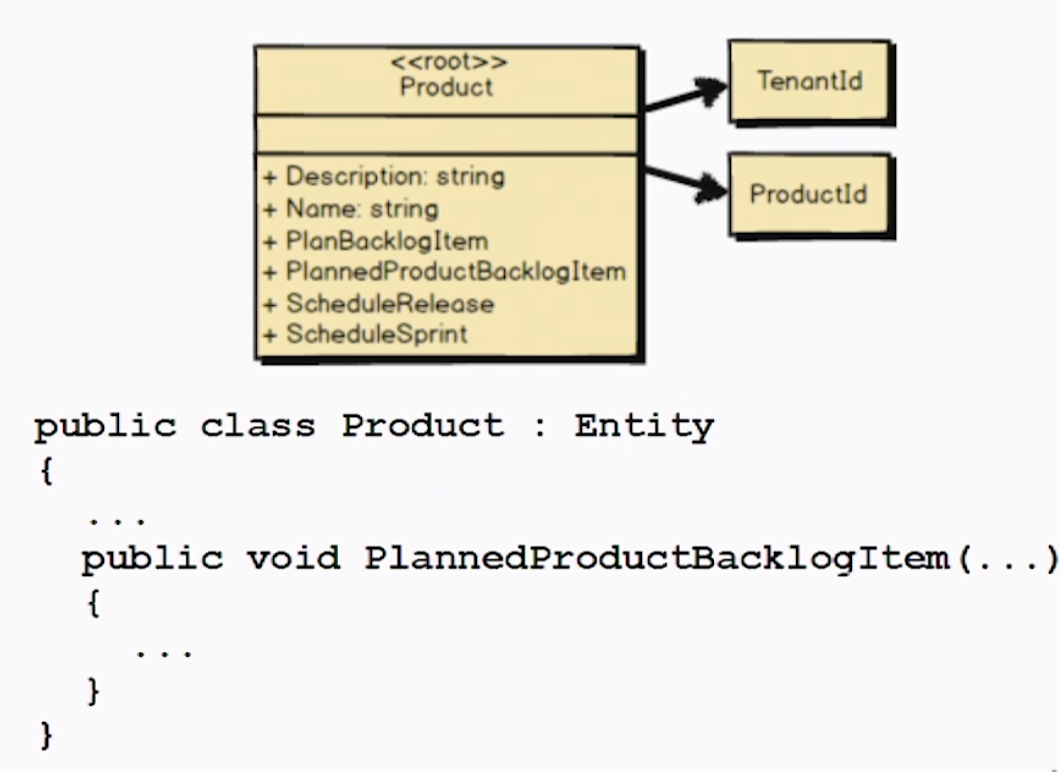
这里增加了一个公开行为:PlannedProductBacklogItem(),是根据敏捷项目的通用语言设计的,会把backlog置为planned(上面说过backlog的三种取值)。UML中还能看到其他行为,总之你需要根据通用语言设计行为定义。这是很重要的DDD实践方法。做为程序员,我们不仅仅是给方法或者聚合根命名,我们要追随我们项目的通用语言进行建模。这样才能满足业务需求,设计出高效的聚合。
明智的抽象
当我们在有界上下文中建模通用语言时,请记住要明智地选择抽象。这里我们看一下我们的核心域,敏捷项目管理应用程序及其通用语言。领域专家说的通用语言自然是使用诸如Product、BacklogItem、Release和Sprint之类的概念。这些是敏捷项目中的自然语言元素或概念。它们很适合,因此在设计敏捷项目管理上下文模型时应牢记这些概念。
但是,在为通用语言建模时,也有可能走完全不同的方向。如果项目的开发人员决定尝试过度抽象模型怎么办?实际上,他们很可能会忽略领域专家所说的自然通用语言,他们没有使用Produc、BacklogItem、Release和Sprint进行建模,而是决定使用类似ScrumElement的名称。可以想一下一个ScrumElement用来表示Product和BacklogItem。毫无疑问,ScrumElement将具有类型名称、字段或属性,当我们用ScrumElement表示Product时,类型名称、字段或属性将被设置为字符串Product,表示BacklogItem时设置为BacklogItem。但是Release和Sprint呢?他们将如何建模?好吧,ScrumElementContainer可能是值得使用的。 ScrumElementContainer将包含ScrumElement集合,并且ScrumElementContainer的类型名称将在表示Release时设置为字符串release,并在表示Sprint时置为sprint。
但是,您是否注意到我们在这里面临的陷阱?我们正和敏捷中自然使用的通用语言对抗。 ScrumElement和ScrumElementContainer没有合适地表示敏捷项目中自然存在的实际具体类型。因此我们考虑一下如果在模型设计中使用错误的抽象将面临的问题。 首先并且最重要的是,你会忽略自然通用语言。其次,很难为特定类型的细节建模。例如,ScrumElement不能完全代表Product或BacklogItem。它代表了更一般的东西。对于复杂的类结构也将有特殊情况。毫无疑问,由于product和BacklogItems之间的差异,会发生特殊情况,并且我们想尽可能地为Product和BacklogItem创建通用的ScrumElement来代表这两个类型,这必然失败,原因在于不同类型的特殊情况很多。与显式建模相比,可能会多写很多代码。通用概念比具体概念需要更多的代码。错误的抽象也会影响用户界面。用户界面将不遵循域模型的基本形状,而域模型是通用语言的自然类型。相反,它将倾向于遵循高度抽象类型的形状。你可能浪费了大量时间、大量金钱,进行的是错误的设计。从长远来看,它将是行不通的。而且还需要花费大量时间来尝试维护和解决特殊情况。这样设计到模型中的以应对将来变化的模型会被时间证明肯定会失败,因为今天的代码到了以后将不会是想象的那样实现。为了避免过分抽象的模型遇到的问题,请根据自然普遍存在的语言显式进行建模。这将创建一个易于理解的模型。领域专家可以理解,因为它确实遵循他们的思维模型。它保护了组织的软件投资,因为节省了时间和金钱。
聚合的大小
什么样子的聚合大小合适?下面是指导流程:
- 首先遵循第二经验法则:设计小聚合。所以一开始,所有聚合都尽可能只有一个实体(就是聚合根),除非你真的确定第二个实体也是必要的。
- 然后应用第一经验法则:在一致性边界内保护业务不变量。画一个表,表里是全部聚合的名称,还有聚合的依赖性,这些依赖性根据业务逻辑会在某个时间范围内更新。
- 第三步是咨询领域专家可接受的时间范围,以使对每个聚合根实体上的每个依赖项进行更新,可能是立即或最终更新。
- 第四,上一步找到的需要强一致性的聚合合并为一个聚合。也就是有依赖且要立即更新的聚合就放到被依赖聚合中。
比如现在有三个聚合:A1,A2,C14。通过和专家讨论了解到:A1和A2必须一起更新,任何时候它俩状态必须一致。那我们就把他俩合并成一个聚合,比如叫A12。但是领域专家说了:A1和C14不用一起更新,半分钟内保持一致就行。那么我们的新聚合A12就得发布一个领域事件,要求C14最终在大约30秒内完成更新
单元测试
我们希望聚合设计可以适应单元测试,这很重要。几节课前我说过使用单元测试作为验收测试,和这里不一样。这些验收测试确实使模型符合领域专家的通用语言设计。因此,在开发通用语言时,会将单元测试做为验收测试。但是现在不一样。根据法则2,设计小型聚合,可以使聚合容易测试。小型聚合比大聚合更易于测试。单元测试不同于验收测试,我们要测试的是每个聚合组件的正确性和鲁棒性。
- 分享到




-

-

